
First Hand Experience on the Path to Continuous Deployment for Docker Containers
Authors note: this is a summary of my session at DevOps Summit NY on June 8, 2017. For details on the session along with slides, visithttp://datagridsys.com/nomorescripts.
Being experienced startup folks we are not scared of bleeding edge tech. For instance, in 2005 we made the jump to virtual machines when most companies hadn't even heard of virtualization, in order to create our cloud platform, AppLogic. This time around we were already very familiar with containers, including many of the limitations, and believed they offered a lot of advantages in speed and cost so we decided to go with Docker running on AWS.
Our engineers have written a lot of apps including both interactive user apps and infrastructure level services and we're pretty adept at creating stateless systems where that's possible. Unfortunately, some of the third party software we needed to use, especially open source, wasn't written with stateless in mind.
For us combining Dev and Ops wasn't a choice, but a necessity. We couldn't afford another hire to run ops. Nonetheless we're fanatics for DevOps and automating everything we can in build, test and deploy. In our case the role of the DevOps guru fell on Pavel, one of our senior engineers. He's well versed in systems architecture as well as most of the systems that needed to be touched by the automation.
Introducing VCTR
The app we were bringing out is called Victor (VCTR for Vulnerabilities and Configuration Tracking and Reporting), a free online service that scans containers and VMs for upgrades that fix critical vulnerabilities. You can check out VCTR here.
As we progressed through development some things worked exceptionally well. New tools including Slack made collaboration among a dispersed team very easy. Build and test tools including Jenkins worked as expected though they were a bit harder to set up than they should be. Docker, despite some minor issues, was more mature than we expected. As you probably have guessed, though, there's a "however" coming. In our case, that "however" was that deployments were still complicated and error prone.
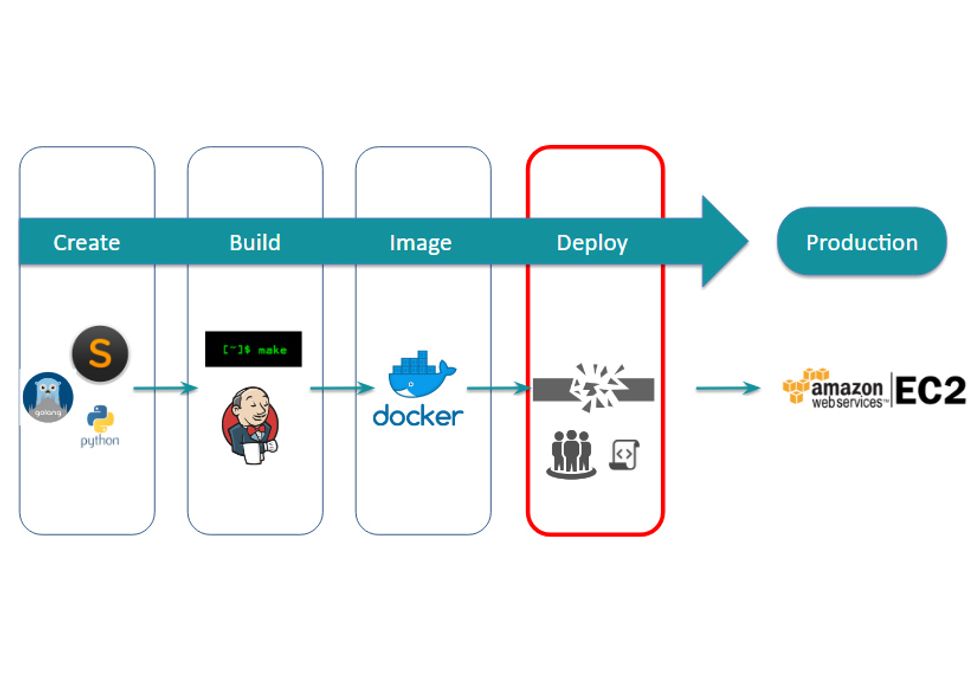
- understand changes -> understand current app -> write script
- test script -> debug -> deploy
- fail -> debug again -> redeploy
- manual rollback...
- give up
The options were minimal. Either we continue to fail through this deployment until we got it right, or find another solution to the problem
Deployment Pain
Despite deployment issues hindering our velocity we needed to push forward with VCTR so we started user engagement while looking for solutions. We assumed we'd find a new tool or pattern in time, but things took an unexpected turn. While implementing VCTR we found other folks having similar deployment issues. Bringing up a new user with VCTR requires installing a small piece of code in the container or VM. That process, not surprisingly, happens in a deployment script and in most cases inserting that one change caused a failure in deployment. In one instance, while on a video call with a user, we watched as a five minute change to one script turned into a two hour debugging marathon involving more than half a dozen scripts. The only folks who didn't have errors after making the change had actually recognized deployment as a significant issue and built their own system for it. Systems, so significant in the amount of time they took to build that they were given names and teams to maintain them. However, those systems were tied to their company's specific architecture and tool chain.
The heart of the problem is that despite articles to the contrary, containers and microservices have dependencies. Some dependencies are simple. For instance, some software still have start order dependencies. Others require configuration differences based on the environment they're running in. Still other require logging in and executing commands after startup. Some dependencies you create yourself. As an example, changing an API requires updates to both the providing and calling services. You might require all updates to be backward compatible, but that's just moving the work to what may be an even more complicated arena. Lastly, what happens when something fails? How do you find out what failed? How do you get back to a functional state?
Despite mounting evidence we didn't initially recognize the pattern. One day over lunch, as the discussion turned from VCTR to deployment issues we realized we'd seen similar problems before when we first tackled cloud deployment. Furthermore, we knew we could solve this. We decided to build a continuous deployment system.
Lessons Learned
We obviously learned a ton about what not to do when setting up a new containerized application. Here's our conclusion of the good and bad of containers, microservices and DevOps:
The good
- Containers, though not perfect, have a rich enough ecosystem of tools to be used in production.
- Microservices architectures are great but don't try to make everything stateless.
- DevOps is the new norm, but you need to go beyond just assigning an engineer the title or merging the folks onto a single team. Ops must take on a new role defining use cases and Dev must embrace Ops.
- Get your tool chain in place from the start. We tried to hack our deployments and as such didn't see the problem for what it was until we were knee deep in it.
The bad
- Deployment remains hard because it's where software meets the real world.
- Deployment requires a system once you get past a few containers. If you don't adopt one, you're going to end up building one - whether you realize it or not.
- Scripts work fine for small apps that don't get updated often, but aren't up to the task for continuous deployment for apps that contain more than a few containers or microservices, especially those that are updated frequently.
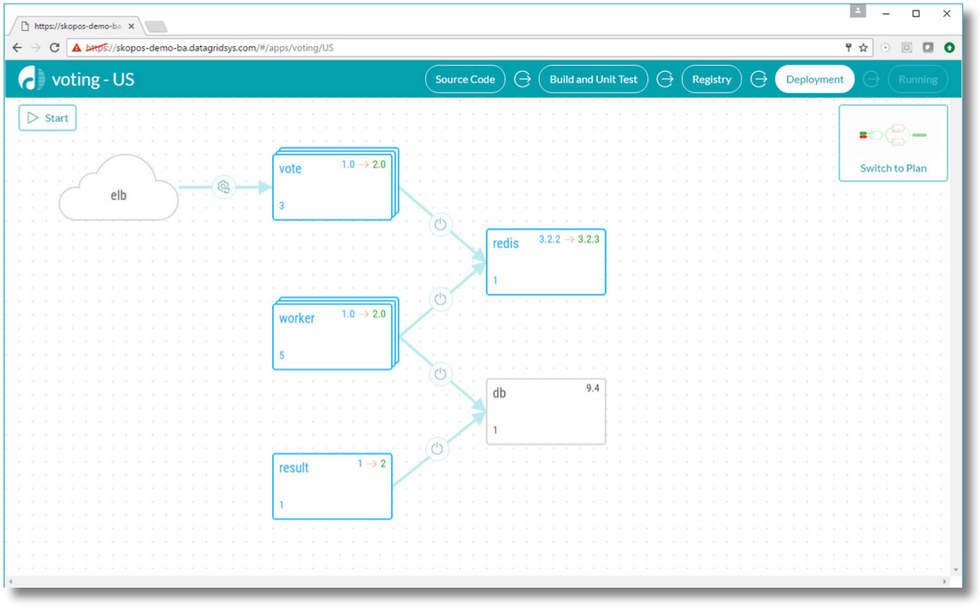
The Result - Continuous Deployment System
We identified key challenge patterns that both ourselves and others faced during deployment and turned them into solutions. One important difference to the other deployment systems we had seen was that we made sure to build for varied environments and architectures. We didn't want this tool to just work for us or rather just the current pattern we were working in. We needed a true system to grow with us. Here are some of the main requirements of our Continuous Deployment system:
- Integrate with popular tool chain elements
- Recognize code and architecture updates
- Provide for identifying dependencies
- Provide for various operating environments
- Automatically deploy authorized updates to operating environments
- Automatically correct for common errors to return proper operation
- Provide meaningful logs and error messages
- Be operable from either UI, API or completely autonomously
We built this deployment system and it's now deploying VCTR on a regular basis. It's also in production at InnoScale and being tested by a handful of DevOps teams who felt the same pain as we did. We're offering the system for free to teams for up to 15 containers.
To learn more about Skopos - our continuous deployment system visit http://datagridsys.com/skopos/.
- 15Five
- 1Password
- 2U, Inc.
- 33Across
- 7Park Data, Inc.
- AAA
- Abbvie
- Accenture
- ActZero.ai
- Adidas
- Adobe Systems Incorporated
- ADP
- AdRoll
- Aetna
- Aetna, a CVS Health Company
- Afterpay
- Airkit
- AlertMedia
- Alloy
- Amazon
- AMC Networks
- American Express Company
- Andela
- Apartment Therapy Media
- Apple
- AppNexus, a Xandr Company
- Arch Insurance
- Arize AI
- Arrow Electronics
- Art Processors
- Asana
- Ask Rachel
- ASM
- Atlassian
- Attune Insurance Services, LLC
- Audible
- Aurora Solar
- Autodesk
- Automattic
- Avaaz
- Avanade
- Avery Dennison
- Back Market
- Bank of America
- Better Companies
- Better Mortgage
- BioRender
- Black Community
- BlackRock
- Blockstack
- Blog
- Bloomberg LP
- Blue Cross and Blue Shield North Carolina
- Bluecore Inc
- Boeing
- BounceX
- Bounteous
- Braintree
- Bridgewater Associates
- Bristol Myers Squibb
- Buffer
- Bumble
- Buzzfeed
- Cable News Network, Inc.
- CallRail
- Calm
- Camunda
- Capco
- Capital One
- Carbon Direct
- CardFlight
- Career and Interview Tips
- CarGurus
- Carvana
- Casper
- CB Insights
- CDW
- Celonis
- CenturyLink Inc.
- Chainalysis Inc.
- charity: water
- Checkr
- CHG Healthcare
- Chingari
- Chubbies
- Ciena
- CircleCI
- Cisco Meraki
- Citi
- Clarus Commerce
- Clarvida
- CLEAR
- CloudBees, Inc.
- Cloudflare
- CLS
- Clyde
- Co-Op
- Cockroach Labs
- Collective Insights
- Collins Aerospace
- Comlinkdata
- Commvault
- Companies That Care
- Compass
- Condé Nast
- Contentful
- Contrast Security
- Convoy
- Costar Group
- CoverMyMeds
- Cribl
- Crowdstreet
- Cruise
- CSL
- CU Direct
- Culture Amp
- Cummins
- Dassault Systemes
- Datadog
- Def Method
- Deliveroo
- Delivery Hero
- Dell Technologies
- Deloitte
- Delphix
- Deutsche Bank AG
- DigitalOcean
- Dishcraft Robotics
- Diversity Reboot Newsletter
- Diversity Reboot Summit 2020 Product Expo
- Diversity Reboot Summit 2021 Virtual Booths
- Diversity Reboot Summit Speakers
- DocuSign
- Dow Jones Company
- DreamSpring
- Dropbox
- Duck Creek Technologies
- DuckDuckGo
- dv01
- Dynatrace
- EDO, Inc
- Elastic
- Enbridge
- Energy Impact Partners
- EnerSys
- Equinix
- Esri
- Expedia Group
- Fair
- FairFrame
- Featured Post
- Featured Talks
- Fidelity
- Flatiron Health Inc
- Flexport, Inc.
- Flocabulary
- Flywheel
- Folsom Labs
- For Employers
- Forbes Media
- Forward
- Freddie Mac
- FTI Consulting
- fuboTV
- G2i
- Gainsight, Inc.
- Gamechanger
- Gantry
- General Assembly
- GitLab
- GoEuro Travel GmbH
- Goldman Sachs
- Good Money
- Google Inc
- GoTo
- Greenhouse Software
- Guru
- Halliburton
- HashiCorp
- Headway
- HealthEdge
- Healthfirst Inc
- Hearst
- Helix
- Helm
- Help Scout
- Hitachi Energy
- Homecare Homebase
- Hopin LTD
- Hult EF
- Hyperloop
- impact-com
- Imply
- In Person Events
- InDebted
- Indeed
- insightsoftware
- Intent
- Intuit
- Intuitive
- Invesco
- Jama Software
- Jamf
- Jemstep
- Jobs
- Johnson & Johnson
- Join Now
- Joor Inc
- Juniper Networks, Inc.
- Justworks
- JW PLAYER
- Kami
- Karat
- Kargo
- Katharine Zaleski's Blog
- Kensho Technologies
- KeyCaliber
- Kin + Carta
- Kinaxis
- Kinesso
- Kiva
- Knotel, Inc.
- L3 Technologies
- Lattice
- LendingClub
- LetsGetChecked
- Liberty Hill Foundation
- Light & Wonder
- LiveSafe
- Lockheed Martin
- Log In
- Logickull
- Logikcull
- Logitech
- Logiworks
- Lyft
- Managed By Q Inc
- Manifold.co
- Marqeta
- Mastercard
- Match.com
- McMaster-Carr Supply
- Meredith Corporation
- Meta
- Metromile, Inc.
- Microsoft Corporation
- Millennium Management
- Mindbody
- MiQ
- Mission
- MongoDB
- Moody's
- Moov Financial
- Morgan Stanley
- Morning Consult
- Motivate
- Munich RE
- MURAL
- MyFitnessPal
- Myriad360
- Nacelle
- nascar
- National Geospatial-Intelligence Agency
- National Security Agency (NSA)
- Nba
- NBCUniversal
- Nestlé
- Netskope
- New Relic
- New York Life Insurance Company
- Nextdoor.com, Inc.
- Nike Inc
- Nokia
- Noodle
- Northrop Grumman
- Novelis Inc.
- Nowsta
- OfferUp
- OkCupid
- Okta, Inc.
- Olive
- One Medical
- OneLogin, Inc.
- OpenTable
- Optoro
- ORTEC
- Oscar Insurance Corp
- OUTFRONT Media Inc.
- Pacific Western Bank
- Packet
- PagerDuty
- Partnership on AI to Benefit People and Society
- Pax Labs Inc
- Pax8
- Paylocity
- Paypal
- Peloton
- PepsiCo
- Philo
- Pitney Bowes Inc.
- PlayStation
- Plectica
- Plenty Of Fish
- Plex
- Pluralsight
- Polis, Inc.
- popular
- PowerToFly Hires
- PowerToFly VIP
- Press
- Previous Event
- Priceline
- Primer
- Procore Technologies Inc
- Product Updates
- Projector
- PromptWorks
- PwC
- pymetrics
- Qualtrics
- Quicken Loans
- Quip
- Random
- RapidScale
- RapidSOS
- Raytheon Technologies
- Realtor.com
- RebelMouse
- RebelMouse Test
- Reddit, Inc.
- Reference Point
- Relativity
- Remote
- Remote Hiring
- Rest Of World
- Ribbon
- Riot Games Inc
- Rockstar Games
- Rover
- RTB House
- S&P Global Inc
- Samsara
- Sapient Consulting
- Sauce Labs
- Schneider Electric
- ScienceLogic
- Scout RFP
- SeatGeek
- SendGrid
- Sentropy Technologies
- Sephora
- ServiceNow
- SevenFifty
- Shield AI
- Shogun
- Shopify Inc.
- Shure
- Siemens
- Skedulo
- Slack Technologies, LLC, a Salesforce company
- Smartsheet Inc.
- Snap Inc.
- SoftwareOne
- Solo Brands
- Solstice
- Sonos
- SoundCloud Inc.
- Spectrum
- Splunk
- Spoiler Alert
- Spot AI
- Spotify
- Stack Overflow
- Stash
- State Listings Inc.
- Stem Disintermedia
- StockX LLC
- Stripe
- Stryker
- SumOfUs
- Sun Life US
- Surescripts LLC
- SV Academy
- Symantec
- Synchrony
- T Rowe Price
- Tackle.io
- Talent Sourcing Trends
- Tandem Diabetes
- Teachers Pay Teachers
- Tech Talk
- Tenable
- Tesla
- Testimonials
- Textio
- Thales Usa Inc.
- The Recycling Partnership
- The Walt Disney Company
- Thomson Reuters
- Thornburg Investment Management
- Thoughtbot
- Thrive Global
- Thumbtack
- Time Inc
- Tinder
- Tiny Mile
- Tiugo Technologies
- TodayTix
- Trail of Bits
- TrussWorks, Inc
- TURO
- Uber
- Ubiquity6
- Udemy
- UiPath, Inc.
- UKG
- United Technologies
- UnitedHealth Group
- Unstoppable Domains
- Upcoming Event
- uShip, Inc.
- Vanguard
- varicent
- Veracode
- Verisign
- Verizon Communications
- Viacom Inc.
- Viasat
- VICE Media Group
- VideoAmp
- Virtu Financial
- Visa
- Vizient
- Vouch Insurance
- Vrbo
- VTS
- Waters Corporation
- Wayfair Inc.
- Webinars
- Wells Fargo Company
- WeWork
- Wolters Kluwer
- Women at Work
- Work & Co
- Work-Life Integration
- Workiva
- WW (Formerly Weight Watchers)
- Yelp Inc.
- YouCanBook.me
- Yougov
- Zapier Inc
- Zendesk, Inc.
- Zeta Global
- Zillow
- Zoom
- ZwillGen
- Zynga





