
Below is an article originally written by Elizabeth Giles at PowerToFly Partner PagerDuty, and published on January 8, 2020. Go to PagerDuty's page on PowerToFly to see their open positions and learn more.
In a story that will sound all too familiar to many developers, in early 2019, I picked up a Kanban ticket to update a legacy system's documentation—a microservice so old that no one on my team really knew much about it. In this blog, I'll share the lessons I learned from familiarizing myself with a legacy system and the positive outcomes of doing so. Additionally, I'll share some steps you can take to look at some of your own legacy systems—if you dare.
When I picked up the ticket, my team was preparing to pass on ownership of the service—one of our oldest and most neglected—to a team that had plans to give it some attention. There were just two things standing between us and changing the PagerDuty escalation policy associated with that service: ensuring that its documentation was up-to-date and having a knowledge transfer session with the new owners.
These were actually bigger hurdles than they sound due to the general lack of knowledge about the legacy service. Nevertheless, I was the developer who ended up with the Kanban ticket to update the service's documentation.
How Did We Get Here?
But how did our team even get to this point to begin with? The service in question was roughly 15,000 lines of Scala code built around 2015 by a completely different team. Over time, the developers who had originally built the service moved on from PagerDuty to new opportunities. Once my team inherited it, we rarely had to touch it for tasks larger than updating some of our tooling.
You see, my team owned a fairly long list of services, many of which we were doing active development on as part of building new features and scaling existing ones. It wasn't a priority for us to devote attention to a service that wasn't involved in any of our new features, rarely caused us operational pain, and wasn't anywhere near the top of our list of scaling bottlenecks.
And then, those from my team who had been around for the original ownership transfer and had done any feature development on the service also moved on. Eventually, we were left with developers who had touched the service a handful of times at best and weren't particularly comfortable with Scala since PagerDuty uses mostly Elixir now. We knew the basics of the service, sure, and we were more familiar with it than folks on other teams, but no one was particularly confident in their knowledge of the details.
(If you're worried after this post that we never go back and improve our legacy systems here at PagerDuty, check out our posts about centralizing scattered business logic in our Elixir webhook service and revisiting our Android architecture.)
Steps to Dive Into an Unfamiliar System
In order to make sure that the documentation was up-to-date and accurate, I did a deep dive to try to resolve some of the gaps in my knowledge.
There are many tips for understanding large, unfamiliar codebases out there (I find Michael Feathers' book, Working Effectively with Legacy Code, particularly helpful), and everyone develops their own techniques, but the steps below are the ones I took to tackle this challenge and could be applied if you're in a similar situation.
Step 1: Reading the Feature Documentation
As developers at PagerDuty, we're fortunate to be in a position to use our own product on a regular basis; however, that doesn't always mean that I'm an expert in all of our feature sets. Because of this, I started by reading the public documentation available for the features this service was powering. This pre-work reading helped me understand the intent and possible edge cases that led to the creation of the code I would end up reading.
Step 2: Tracing Requests
When I was ready to start diving into the codebase, I began by giving myself logical paths to follow by identifying where HTTP requests and other inputs entered the system and tracing through what happened with them from there. I then created a flow diagram so that I didn't have to rely on memory to keep track of everything.
Step 3: Examining the Data Lifecycles
Many services accept multiple types of requests that all interact in different ways with data that the service is storing. In these cases, it can be difficult to get a good view of how the entire system works when tracing one type of request at a time. To address that, after tracing individual requests, I took a step back and focused on the pieces of data being stored to understand their lifecycles—how they were created, updated, accessed, and deleted.
Step 4: Refactoring
Once I gained a better understanding of the system, I checked those assumptions by trying to make changes to the code, usually some refactoring, to try to make it more comprehensible. If the changes seemed to work, and didn't cause compiler errors, break tests, or cause the system to behave in a way that didn't match its feature documentation, I could be fairly confident that my assumptions were valid.
Often throughout this process, I was making changes purely for learning purposes with the full intention of reverting them afterwards. This meant that I could move faster and focus on understanding the service rather than following all conventions or what level of risk I was willing to take with the new changes.
Step 5: Explaining the Service
Once I felt fairly confident in my understanding, the last thing I did was to try and explain how the service worked—sometimes to another person and sometimes to a rubber duck. Either way, questions or gaps would come up that made me realize there were still parts of the service I needed to investigate further.
When You Learn More Than You Expect
By the end of the above process, I had a much better understanding of how the service actually worked as well as a good start on the documentation that I needed to write.
The service in question was used to enable some of PagerDuty's many integrations. Essentially, it stored information about different actions to be taken for each integration and provided interfaces for accessing and updating those actions.
This simplifies the real service quite a bit, but as an illustration, I ended up with some notes like this to describe how it handled requests:
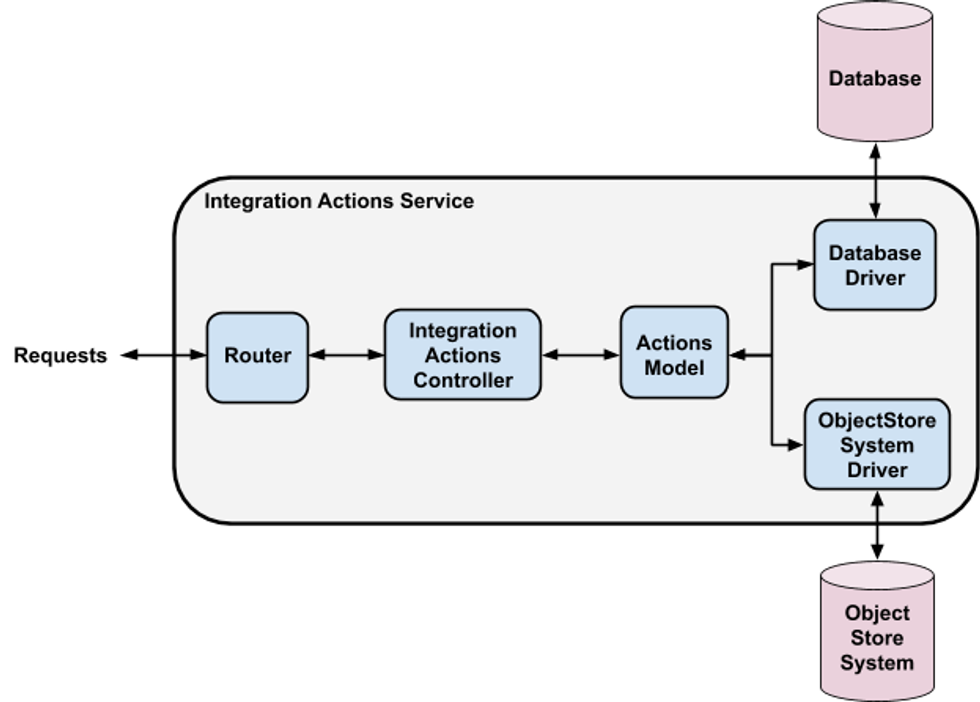
POST /:integration_id/actions
- Fetch the metadata for the current version of the integration from the database.
- Insert a new entry into the database with metadata for the new version, with an incremental version number.
- Store the full set of actions for the new version of the integration in the object store system under the path included in the database entry.
- Mark the new database entry as "active."
- Mark the database entry for the previous version as "not active."
GET /:integration_id/actions
- Fetch the metadata for the current version of the given integration from the database.
- Use the path included in the metadata to fetch the full set of actions for the integration from the object store system.
And thus, I ended up with notes like this to describe the lifecycle of a row of the integration metadata table being stored in the database:

POST /3/actions
- INSERT: Row 55 is inserted into the database as a result of a request to update integration #3.
- UPDATE: The
activecolumn of row 55 is updated totrue, after the full actions set from the request has been stored in the object store system.
GET /3/actions (any number of times)
- SELECT: The data in row 55 is returned as a result of a query to the database for the most recently created entry with
integration_id=3andenabled=true.
POST /3/actions
- SELECT: Row 55 is returned as the current integration version as a result of a query to the database to find an entry with
integration_id=3andactive=true. - UPDATE: After the new version of the integration is completely deployed, the
activecolumn of row 55 is updated tofalse.
This wasn't a substitute for having built the service or done substantial work on it myself, but it was a fairly quick process that enabled me to come to a stronger understanding of the service and opened my eyes to a few unexpected realizations.
A Bug Appears!
Let's go back to the lifecycle of a database row for a minute.
You may have noticed, as I did, that the service had two different ways of fetching the "current" version of an integration from the database, based on two similar sounding columns, enabled and active. This came as a result of gradual additions of features to the service and gradual evolutions of the data model to support them. I promise that it's much easier to see in the simplified version of the service that I've described here than it was in reality.
When I did notice this, I realized that I had inadvertently identified the source of a long-running annoyance for my team.
We had been aware for some time that this service would briefly return error responses to GET requests for a specific integration while a new version of that integration was being created. If we were ever notified about an incident on the service during an integration deploy, we knew that it would most likely be transient and nothing to worry about.


However, it had never been worth our time to investigate the issue due to our lack of familiarity with the service, the fact that errors were retried so there was no customer impact, and the general rarity of new integration deploys that only ever happened during business hours anyway. So we just treated it like one of the unavoidable quirks that you tend to find in legacy systems.
In my dive into the service, I discovered that those errors were occuring because of its multi-step process for responding to POST requests, where a new row containing integration metadata was first inserted into the database and then the full set of actions corresponding to the new integration version was persisted in our object store system. When GET requests were received by the service between the database insertion and the persistence of the actions, the service wouldn't be able to find actions in the object store system under the path specified in the database for the "current" version of the integration.
This meant that the operational noise we had been seeing was actually very easily avoidable and wasn't some complex issue inherent in the design of the service. We were already setting the active column for a row in the database to true only when the actions associated with that row were fully persisted, and were using that column elsewhere as our method for identifying the "current" integration version. So if we adjusted GET requests to also query the database only for rows with active=true, the errors during deploys would be eliminated.
I took a couple of hours to do just that during our next Hackday, and we haven't had problems since!
What Learning a Legacy System Can Do for You
The experience of diving deeper into this particular legacy system has helped me recondition how I think about legacy systems in general.
I'm certainly not going to argue that it's vital for developers to always be equally familiar with all of the services that they own, including legacy ones, to the point of getting into a cycle of rewrites every couple of years. But I feel more strongly now about a middle ground, where if a team has a general lack of confidence in their understanding of a system, it could be valuable to take a day or two to try to fix that.
When learning about your legacy systems:
- You can often identify quick improvement wins when you're looking at a system with fresh eyes from a holistic perspective (like I did in this example). Even if you can't make the improvements right away, it can be nice to have a shortlist of them sitting around to work on when you have gaps between larger projects.
- You can gain a better understanding of which parts of the system are most likely to break and how soon those failures might happen, which can be useful when planning for the future. Even if you have no immediate plans to make changes, no system fulfills its purpose and scales forever without some form of attention.
- If you've decided that you're going to be completely replacing your legacy system, you can get a head start on figuring out the challenges of the problem space and identifying edge cases in behavior that you will want to take into account in your replacement system.
Understanding how a legacy system works isn't likely to be the biggest challenge involved in owning it. But making a small investment in that area will help you with any of the other challenges that you end up facing.
Do you have opinions and/or horror stories about dealing with legacy systems? Or perhaps a favorite process for understanding how an unfamiliar system works? We'd love to hear from you in our Community forums.
- 15Five
- 1Password
- 2U, Inc.
- 33Across
- 7Park Data, Inc.
- AAA
- Abbvie
- Accenture
- ActZero.ai
- Adidas
- Adobe Systems Incorporated
- ADP
- AdRoll
- Aetna
- Aetna, a CVS Health Company
- Afterpay
- Airkit
- AlertMedia
- Alloy
- Amazon
- AMC Networks
- American Express Company
- Andela
- Apartment Therapy Media
- Apple
- AppNexus, a Xandr Company
- Arch Insurance
- Arize AI
- Arrow Electronics
- Art Processors
- Asana
- Ask Rachel
- ASM
- Atlassian
- Attune Insurance Services, LLC
- Audible
- Aurora Solar
- Autodesk
- Automattic
- Avaaz
- Avanade
- Avery Dennison
- Back Market
- Bank of America
- Better Companies
- Better Mortgage
- BioRender
- Black Community
- BlackRock
- Blockstack
- Blog
- Bloomberg LP
- Blue Cross and Blue Shield North Carolina
- Bluecore Inc
- Boeing
- BounceX
- Bounteous
- Braintree
- Bridgewater Associates
- Bristol Myers Squibb
- Buffer
- Bumble
- Buzzfeed
- Cable News Network, Inc.
- CallRail
- Calm
- Camunda
- Capco
- Capital One
- Carbon Direct
- CardFlight
- Career and Interview Tips
- CarGurus
- Carvana
- Casper
- CB Insights
- CDW
- Celonis
- CenturyLink Inc.
- Chainalysis Inc.
- charity: water
- Checkr
- CHG Healthcare
- Chingari
- Chubbies
- Ciena
- CircleCI
- Cisco Meraki
- Citi
- Clarus Commerce
- Clarvida
- CLEAR
- CloudBees, Inc.
- Cloudflare
- CLS
- Clyde
- Co-Op
- Cockroach Labs
- Collective Insights
- Collins Aerospace
- Comlinkdata
- Commvault
- Companies That Care
- Compass
- Condé Nast
- Contentful
- Contrast Security
- Convoy
- Costar Group
- CoverMyMeds
- Cribl
- Crowdstreet
- Cruise
- CSL
- CU Direct
- Culture Amp
- Cummins
- Dassault Systemes
- Datadog
- Def Method
- Deliveroo
- Delivery Hero
- Dell Technologies
- Deloitte
- Delphix
- Deutsche Bank AG
- DigitalOcean
- Dishcraft Robotics
- Diversity Reboot Newsletter
- Diversity Reboot Summit 2020 Product Expo
- Diversity Reboot Summit 2021 Virtual Booths
- Diversity Reboot Summit Speakers
- DocuSign
- Dow Jones Company
- DreamSpring
- Dropbox
- Duck Creek Technologies
- DuckDuckGo
- dv01
- Dynatrace
- EDO, Inc
- Elastic
- Enbridge
- Energy Impact Partners
- EnerSys
- Equinix
- Esri
- Expedia Group
- Fair
- FairFrame
- Featured Post
- Featured Talks
- Fidelity
- Flatiron Health Inc
- Flexport, Inc.
- Flocabulary
- Flywheel
- Folsom Labs
- For Employers
- Forbes Media
- Forward
- Freddie Mac
- FTI Consulting
- fuboTV
- G2i
- Gainsight, Inc.
- Gamechanger
- Gantry
- General Assembly
- GitLab
- GoEuro Travel GmbH
- Goldman Sachs
- Good Money
- Google Inc
- GoTo
- Greenhouse Software
- Guru
- Halliburton
- HashiCorp
- Headway
- HealthEdge
- Healthfirst Inc
- Hearst
- Helix
- Helm
- Help Scout
- Hitachi Energy
- Homecare Homebase
- Hopin LTD
- Hult EF
- Hyperloop
- impact-com
- Imply
- In Person Events
- InDebted
- Indeed
- insightsoftware
- Intent
- Intuit
- Intuitive
- Invesco
- Jama Software
- Jamf
- Jemstep
- Jobs
- Johnson & Johnson
- Join Now
- Joor Inc
- Juniper Networks, Inc.
- Justworks
- JW PLAYER
- Kami
- Karat
- Kargo
- Katharine Zaleski's Blog
- Kensho Technologies
- KeyCaliber
- Kin + Carta
- Kinaxis
- Kinesso
- Kiva
- Knotel, Inc.
- L3 Technologies
- Lattice
- LendingClub
- LetsGetChecked
- Liberty Hill Foundation
- Light & Wonder
- LiveSafe
- Lockheed Martin
- Log In
- Logickull
- Logikcull
- Logitech
- Logiworks
- Lyft
- Managed By Q Inc
- Manifold.co
- Marqeta
- Mastercard
- Match.com
- McMaster-Carr Supply
- Meredith Corporation
- Meta
- Metromile, Inc.
- Microsoft Corporation
- Millennium Management
- Mindbody
- MiQ
- Mission
- MongoDB
- Moody's
- Moov Financial
- Morgan Stanley
- Morning Consult
- Motivate
- Munich RE
- MURAL
- MyFitnessPal
- Myriad360
- Nacelle
- nascar
- National Geospatial-Intelligence Agency
- National Security Agency (NSA)
- Nba
- NBCUniversal
- Nestlé
- Netskope
- New Relic
- New York Life Insurance Company
- Nextdoor.com, Inc.
- Nike Inc
- Nokia
- Noodle
- Northrop Grumman
- Novelis Inc.
- Nowsta
- OfferUp
- OkCupid
- Okta, Inc.
- Olive
- One Medical
- OneLogin, Inc.
- OpenTable
- Optoro
- ORTEC
- Oscar Insurance Corp
- OUTFRONT Media Inc.
- Pacific Western Bank
- Packet
- PagerDuty
- Partnership on AI to Benefit People and Society
- Pax Labs Inc
- Pax8
- Paylocity
- Paypal
- Peloton
- PepsiCo
- Philo
- Pitney Bowes Inc.
- PlayStation
- Plectica
- Plenty Of Fish
- Plex
- Pluralsight
- Polis, Inc.
- popular
- PowerToFly Hires
- PowerToFly VIP
- Press
- Previous Event
- Priceline
- Primer
- Procore Technologies Inc
- Product Updates
- Projector
- PromptWorks
- PwC
- pymetrics
- Qualtrics
- Quicken Loans
- Quip
- Random
- RapidScale
- RapidSOS
- Raytheon Technologies
- Realtor.com
- RebelMouse
- RebelMouse Test
- Reddit, Inc.
- Reference Point
- Relativity
- Remote
- Remote Hiring
- Rest Of World
- Ribbon
- Riot Games Inc
- Rockstar Games
- Rover
- RTB House
- S&P Global Inc
- Samsara
- Sapient Consulting
- Sauce Labs
- Schneider Electric
- ScienceLogic
- Scout RFP
- SeatGeek
- SendGrid
- Sentropy Technologies
- Sephora
- ServiceNow
- SevenFifty
- Shield AI
- Shogun
- Shopify Inc.
- Shure
- Siemens
- Skedulo
- Slack Technologies, LLC, a Salesforce company
- Smartsheet Inc.
- Snap Inc.
- SoftwareOne
- Solo Brands
- Solstice
- Sonos
- SoundCloud Inc.
- Spectrum
- Splunk
- Spoiler Alert
- Spot AI
- Spotify
- Stack Overflow
- Stash
- State Listings Inc.
- Stem Disintermedia
- StockX LLC
- Stripe
- Stryker
- SumOfUs
- Sun Life US
- Surescripts LLC
- SV Academy
- Symantec
- Synchrony
- T Rowe Price
- Tackle.io
- Talent Sourcing Trends
- Tandem Diabetes
- Teachers Pay Teachers
- Tech Talk
- Tenable
- Tesla
- Testimonials
- Textio
- Thales Usa Inc.
- The Recycling Partnership
- The Walt Disney Company
- Thomson Reuters
- Thornburg Investment Management
- Thoughtbot
- Thrive Global
- Thumbtack
- Time Inc
- Tinder
- Tiny Mile
- Tiugo Technologies
- TodayTix
- Trail of Bits
- TrussWorks, Inc
- TURO
- Uber
- Ubiquity6
- Udemy
- UiPath, Inc.
- UKG
- United Technologies
- UnitedHealth Group
- Unstoppable Domains
- Upcoming Event
- uShip, Inc.
- Vanguard
- varicent
- Veracode
- Verisign
- Verizon Communications
- Viacom Inc.
- Viasat
- VICE Media Group
- VideoAmp
- Virtu Financial
- Visa
- Vizient
- Vouch Insurance
- Vrbo
- VTS
- Waters Corporation
- Wayfair Inc.
- Webinars
- Wells Fargo Company
- WeWork
- Wolters Kluwer
- Women at Work
- Work & Co
- Work-Life Integration
- Workiva
- WW (Formerly Weight Watchers)
- Yelp Inc.
- YouCanBook.me
- Yougov
- Zapier Inc
- Zendesk, Inc.
- Zeta Global
- Zillow
- Zoom
- ZwillGen
- Zynga





